Insurance fraud has been since the beginning of the insurance organisation. When a person makes a false claim in order to get benefits to which they are not entitled is known as an insurance fraud. Insurance fraud is a serious problem, this is far from a victimless crime. The loss to insurance companies due to fraud results in the need to raise insurance rates, increased premium cost, trust deficit during the claims process.
So detection of fraud is a challenging problem for an insurance industry. In this article we discuss how machine learning is helpful for detecting fraud in insurance claims.
Table of Contents
Why Machine Learning:
Registered Insurance Company would have the capacity to examine each and every case and detect whether it is genuine or not, but this approach is not only time consuming but also costly. As per the information gathered, the most efficient strategy so far, to detect Insurance fraud is, we can use computerized techniques. Data Scientists can use Machine Learning techniques to reduce human efforts. This will give edge over redundant manual processes.
Benefits of Machine learning:
- All the claims which are not genuine or suspected can be detected using ML.
- By machine learning we can give a featured structure to the dataset, or can process data in a short interval of time.
- Machine learning works better with an abundance of data or historical data. Machine Learning Technique will help to detect the similarities or differences between the multiple data behaviours. This would require proper model training to detect
- The main importance lies in efficiency. Since machines work faster than manual inspection done by human intervention. Then we can say that use of machine learning techniques in detecting frauds or potential fraud is a time saving and efficient approach.
Technology used in fraud detection process:
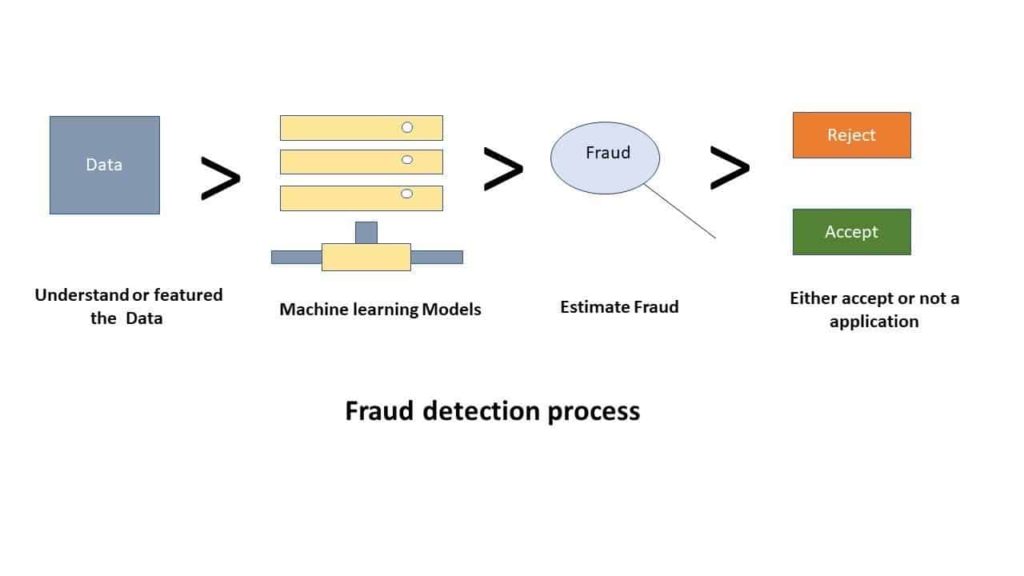
Following are the steps that we will follow in fraud detection process:
- Understanding of data: First and most important task is to understand the data, make data from raw to featured, and completely understand each feature that affects the target variable (dependent variable). Target variable is binary, that is: fraud or not (yes or no). We split the data into test and train sets.
- Provide training sets: By training sets we usually mean the data on which we train our model that includes both fraud and genuine cases. So that machine easily learns about both the cases and understands the pattern of the data, to make future predictions on the new data.
- Building model: The next task is the selection of the model, which model is suitable according to our data. We firstly understand whether we are doing a regression problem or classification problem. In our case this is a classification problem. (either the claim is fraud or not) we have several models for this like logistic regression, random forest, decision tree etc. In our case we use random forest to get a higher accuracy. Accuracy is estimated by calculating confusion matrix.
- Results from our data: Actually, we have a dataset that includes 36 features out of which 35 are independent variables(variables that affect the target variables) and one is dependent variable. (target variable: fraud or not) we train the models and get the accuracy of about 85% on the test data. Complete structure and results on test data are like this:
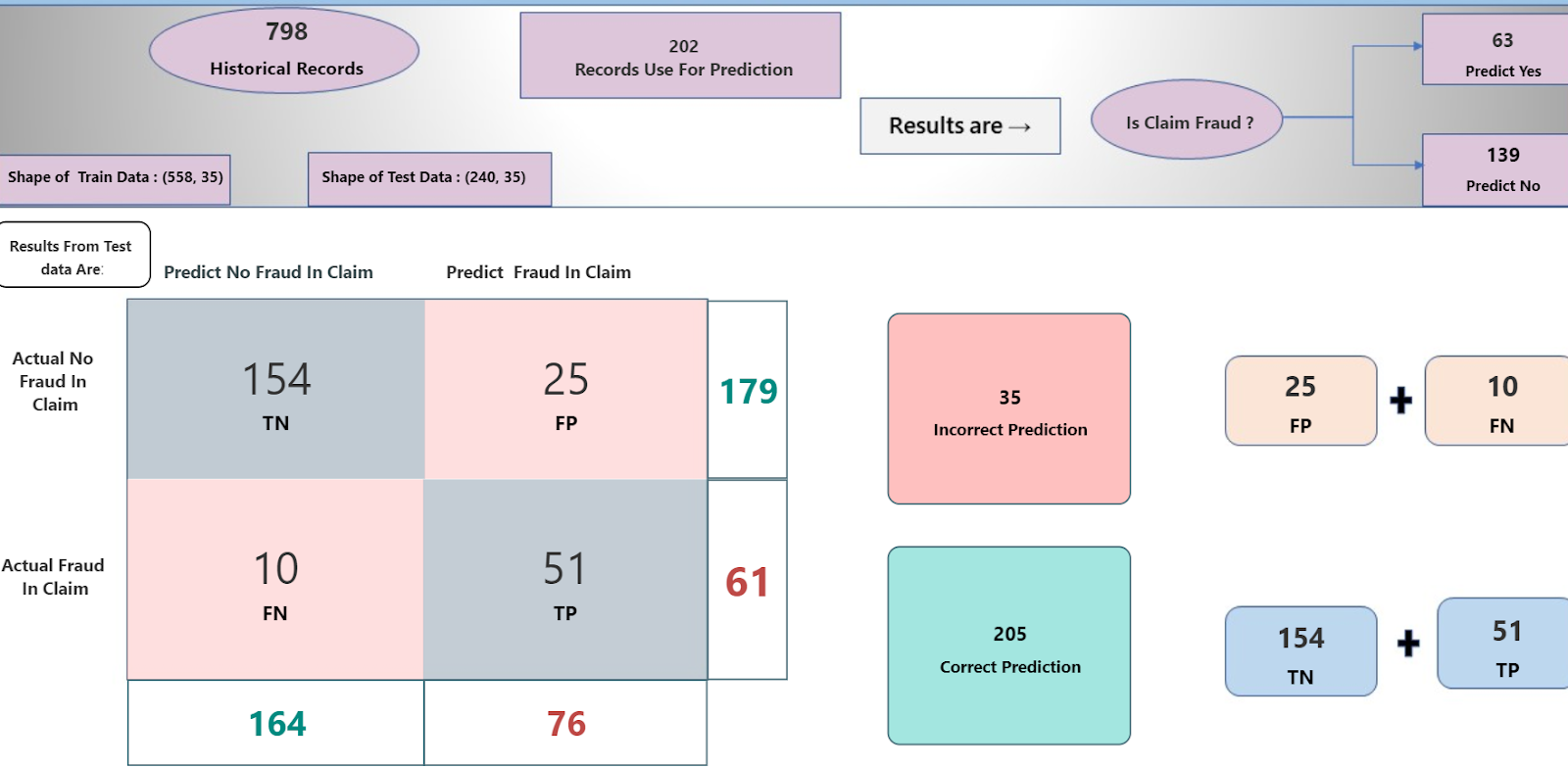
Here we can clearly see that test data includes 240 records out of which 35 are incorrectly predicted by our model and 205 are correct predictions. Confusion matrix indicates that 25 predictions are false positive and 10 are false negative, as displayed in the above snapshot.
These two values are the indication of error and tell us how many errors are present in our model. Hence by using this approach we can easily make predictions on new data to check either the claim is fraud or not.
As you can see in the above diagram that I fed a total 203 new applications on my model and it gives me 63 are fraud and 139 are genuine claims. So we automate the process of fraud in insurance claims in the short interval of time by using a machine learning approach.
We can also see that how much each feature is important or we can easily detect which are the important features which affect the target variable most as shown in the fig:

Here we can easily see that the incident severity (67%) affects the target variable most. Hence this feature is of great importance.
Conclusion:
Hence, we can conclude that machine learning is a most popular field among industry experts. After using this approach we can easily detect the potential frauds in the claims and also probability of fraud. By using this approach, we can early detect the frauds and this will be helpful in:
- Reduction in fraud investigation expenses.
- Lowers claim handling cost
- Efficiently manages claims severity
- Detection of early claims in the claim life cycle is paramount to managing overall claims costs.
Hence, we can say that the use of machine learning approaches for insurance companies is very beneficial and efficient in the claims fraud detection process.


