Credit-lending is an old industry for more than 20 decades and cater to major functions of banks and financial institutions. Credit has its own prominence in human lives and in all industries that involve monetary transactions in some forms.
Throughout the years, the lending industry has grown rapidly with the elevation of fraudulent activities. People can take loans for multiple purposes. Both lender and borrower play their cards to earn maximum benefits from loan activities.
Meanwhile customer relationship management also Investors provide loan to borrowers in exchange to earn in form of interest and get repaid on it. But in case the borrower failed on his part to repay the loan, the lender may lose the profit.
Well now the important question arose by a lender:
- Should we approve the loan?
- After approval, whether the borrower will repay the loan?
Bothbefore and after loan approval case need proper credit analysis andattention because if the lender is too strict means fewer loans get approved therefore less interest to collect and if not, he/she may end up with default loan. So, this requires an extensive study of loan behavior and customer activities which is surely not an easy task to perform.
The rise of machine learning and big data processing has changed the whole process of lending drastically. Machine learning is a method of learning where computer import data, understand it, and then make predictions on future data by previous encounters. These models can be made only with historical data say the history of loan records of customers maintained by the lenders.
Table of Contents
A summary to Journey
This journey begins with data, rises in the bags of data generation sources has opened many ways to gather more data to underwrite loans like
- Gathering data from customers and organizations
- Maintaining follow up records
- Hiring agencies for loan tracker
Data analysis tools used to discover previously unknown, valid patterns, and relationships in large datasets. It’s like opening each data feature to its core called data mining. Data analysis is very important to determine how the relationship lies between each feature affecting loan status, this is done with the help of exploratory data analysis. It is highly recommended to perform EDA whenever there is data because one always finds some hidden story. Before jumping to model generation
“let’s play with data”
- How messy the data is? ____________________ let the cleaning begin
- Is there any missing value? _______________ Too many, either fill those with average, mode and backward-forward technique or remove them based on data story.
- Oops data is highly imbalanced _____________ now find the most suitable strategy to deal with imbalanced data (ignoring this step means putting the accuracy of model at stake)
- Apart from the above steps, there can be others based on data requirements.
The lender may provide numerous amounts of data or features for prediction models. But the most important task is selecting the features that are most important or most relevant for prediction. This process is called feature selection.
Feature Selection
Machine learning cannot accommodate a large number of features, so it is often necessary to do conditionality reduction to decrease the number of feature for better situations and improving performance. This can be done by
- Permutation feature importance: determine the best features to use by computing the feature importance score in respect of predicting feature.
- Correlation-based feature selection: identify columns in input data that have the greatest correlation power with output data.
Train to the efficient lending process
Preparing data for training and testing performance, it’s always better to have some data in hand to validate the model performance. Also, final data on which prediction is performed. There is various modeling technique for prediction. Predicting loan repayment capabilities and loan approval status both problems lie under a classification technique – a predictive modeling technique. In a classification problem, the outputs are categorical or discrete nature.
There are powerful algorithms in supervised models like logistic regression, K nearest neighbors (KNN), gradient boosting, random forest, decision tree, support vector machine (SVM), and neural networks are shown great interest in increasing efficiency, speed, and accuracy of tasks performed by a credit analyst. There is no definite formula for selecting algorithms. One may work on some data may not work on others. So better to evaluate models with cross-validation to get reliable results.
Case – Loan Approval Prediction (Approved Vs Not Approved)
Customer applies for the loan and only gets approved if his/her eligibility for loan proven unquestionable. Validation of customer eligibility based on customer information is hectically job that needs automation. A machine learning algorithm provides a helpful hand in the loan approval process like
- Identify customer segment are highly prone to loan approval.
- How loan details affecting status like purpose, loan period, loan amount, etc.
- Applicant income and number of dependents have its own importance in the prediction process.
- Identify factors that play crucial role in predicting loan status.
- How demographic profile of customers affect loan approval.
- It takes credit score into consideration
- The best way to determine creditworthiness is credit history which also has been taken into account.
Out of models mention above random forest classifiers stand out at its best with 86% accuracy. For validating, 123 loan applications were taken, results for which has shown below. Efforts have been made to reduce False Positive (FP) as it is more prone loss than false negative (FN) cases. As the loan that must not be approved has predicted approved count by False Positive cases.
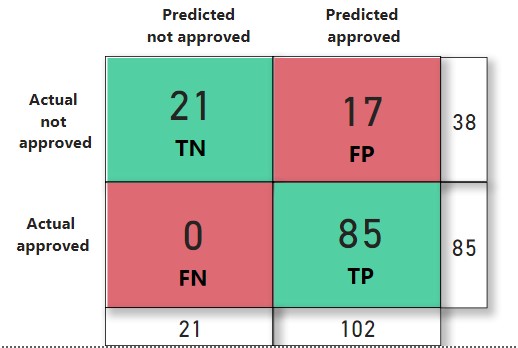
How much percentage each feature contributed to predicting loan approval status on data provided also can be known. This result is generated by model itself.
Case – Loan Repayment Status (Fully Paid Vs Charged Off)
Once the loan approved, it is important to follow up the loan for the future as sometimes the borrower failed to repay the loan amount and interest deliberately or reasonably. In both the situation lender face loss of funds. So in part of lender, machine learning automate system provide a solution by predicted loan repayment status i.e. whether the loan will be fully paid or not (charged off) by studying past behavior and previous customer records. Machine learning models identify those loans which have more probability to end up being charged off. Given can be the details required for prediction:
- Annual Income of borrower
- Tax Liens
- Current loan amount
- Maximum open credit
- Current credit balance
- Bankruptcies
- Interest rate
- Installment
- Debt to income ratio
- Purpose
- Month since last delinquent
- Number of credit problems, other details can be entertained by the lender
After performing machine learning algorithms, Gradient Booster Classifier outperforms the best among all models with 93.49% accuracy. The validation result on 10146 cases is as follows. The model performs really well as it succeeds in reducing False Positive cases as they are more loss prone.
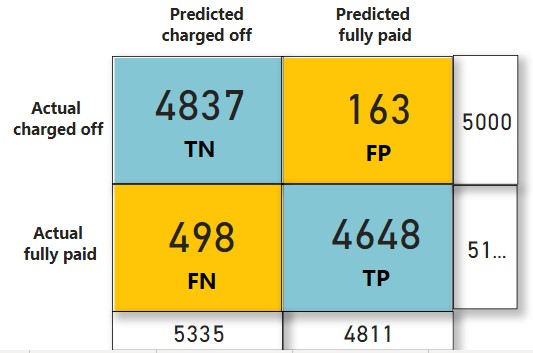
Based on the feature provided by bank given is feature importance percentage for prediction:

Note: All the results have shown above are completely based on data, may change accordingly with the data provided.
Conclusion:
- With the continuous increase in the number of loan defaulters, results in a huge financial loss to the bank. If there is a way to efficiently classify loaners’ status in advance, it would be boon to lending business.
- In the machine learning system proper procedures have taken for reliable results. Proper data cleaning and exploratory analysis done, efforts are made to achieve maximum accuracy and explanatory results. Also, each outcome has its own score of probability.
- All algorithms assume that the future is the reflection of the past. This model acts as an important suggestion and early warning tool for default activities.


